| Date | Time | Details |
|---|---|---|
| 2026-04-23 | 6:00pm ET | Pre-Assignment #11 Due |
| 2026-04-24 | 11:59pm ET | Mini-Project #03 Due |
| 2026-04-30 | 6:00pm ET | Pre-Assignment #12 Due |
| 2026-05-03 | 11:59pm ET | Mini-Project Peer Feedback #03 Due |
| 2026-05-07 | 6:00pm ET | Final Project Presentation Slides Due |
| 2026-05-14 | 6:00pm ET | Pre-Assignment #14 Due |
| 2026-05-15 | 11:59pm ET | Mini-Project #04 Due |
Software Tools for Data Analysis
STA 9750
Michael Weylandt
Week 10 – Tuesday 2026-04-21
Last Updated: 2026-04-21
Chloropleths
A map whose fill depends on the value of interest is called a chloropleth:
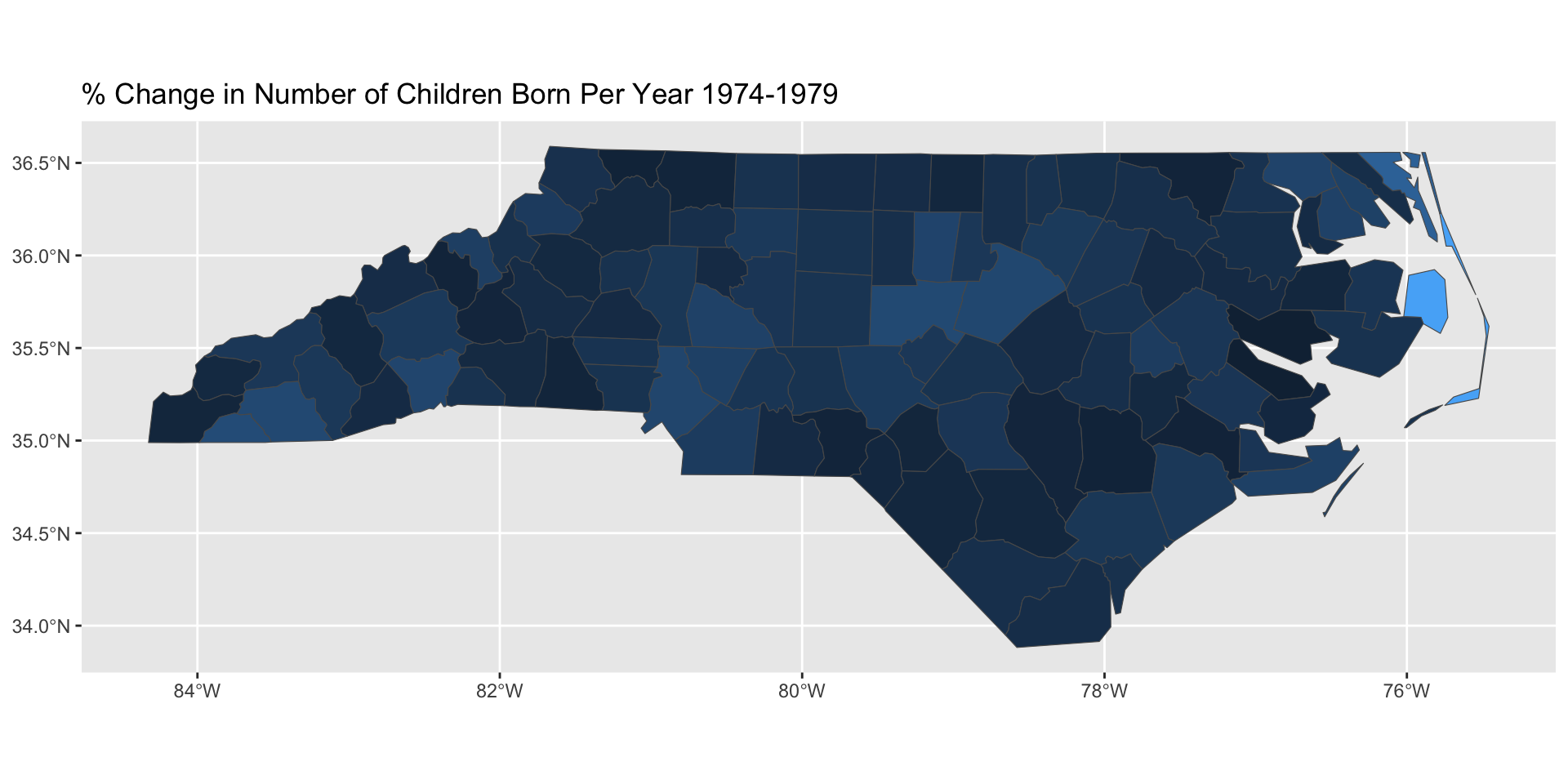
Integrates well with ggplot2:
geom_sfknows how to handle geometries- other features all work as expected (fill, animation, legends, etc.)
transition_*() functions
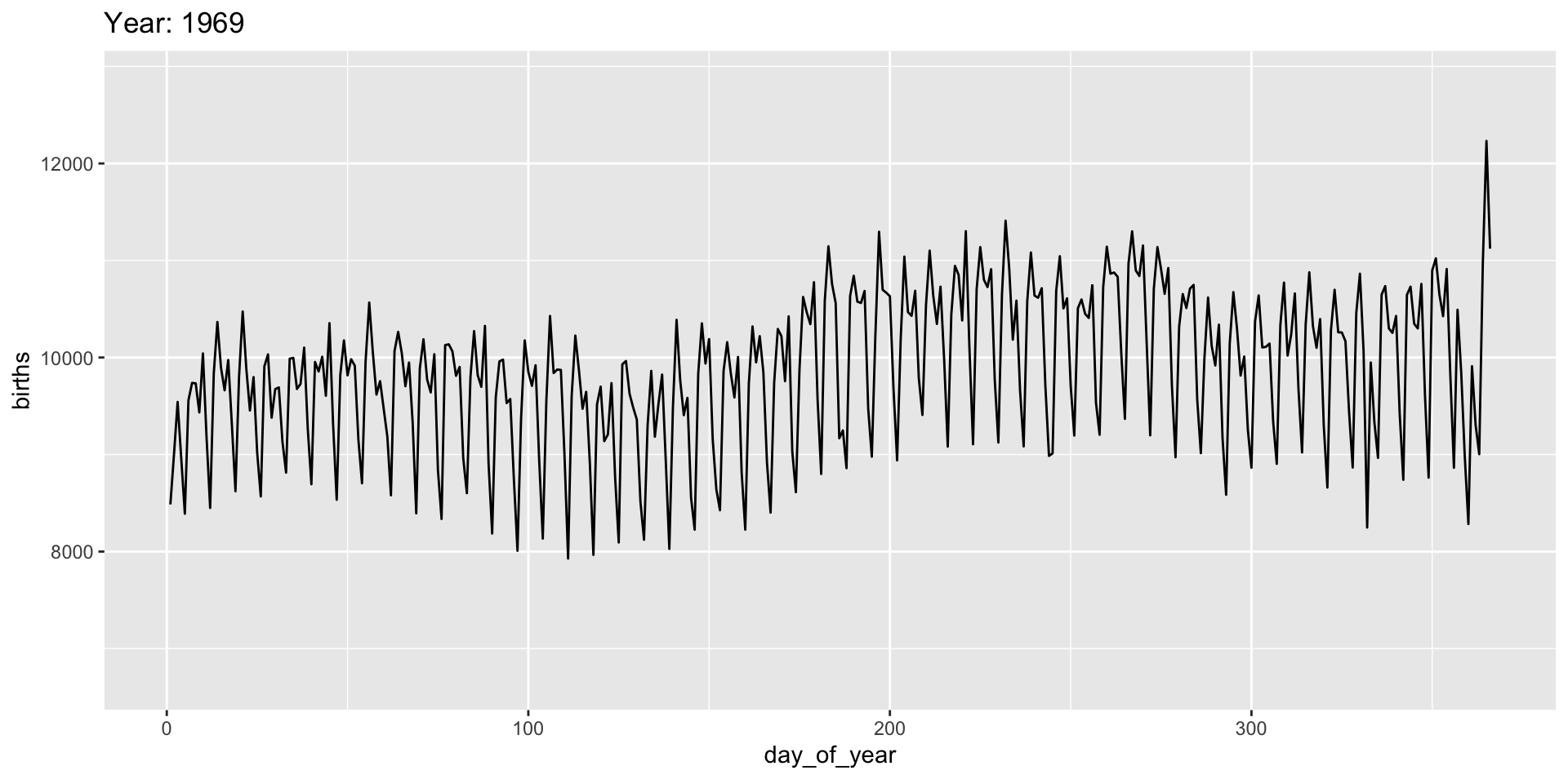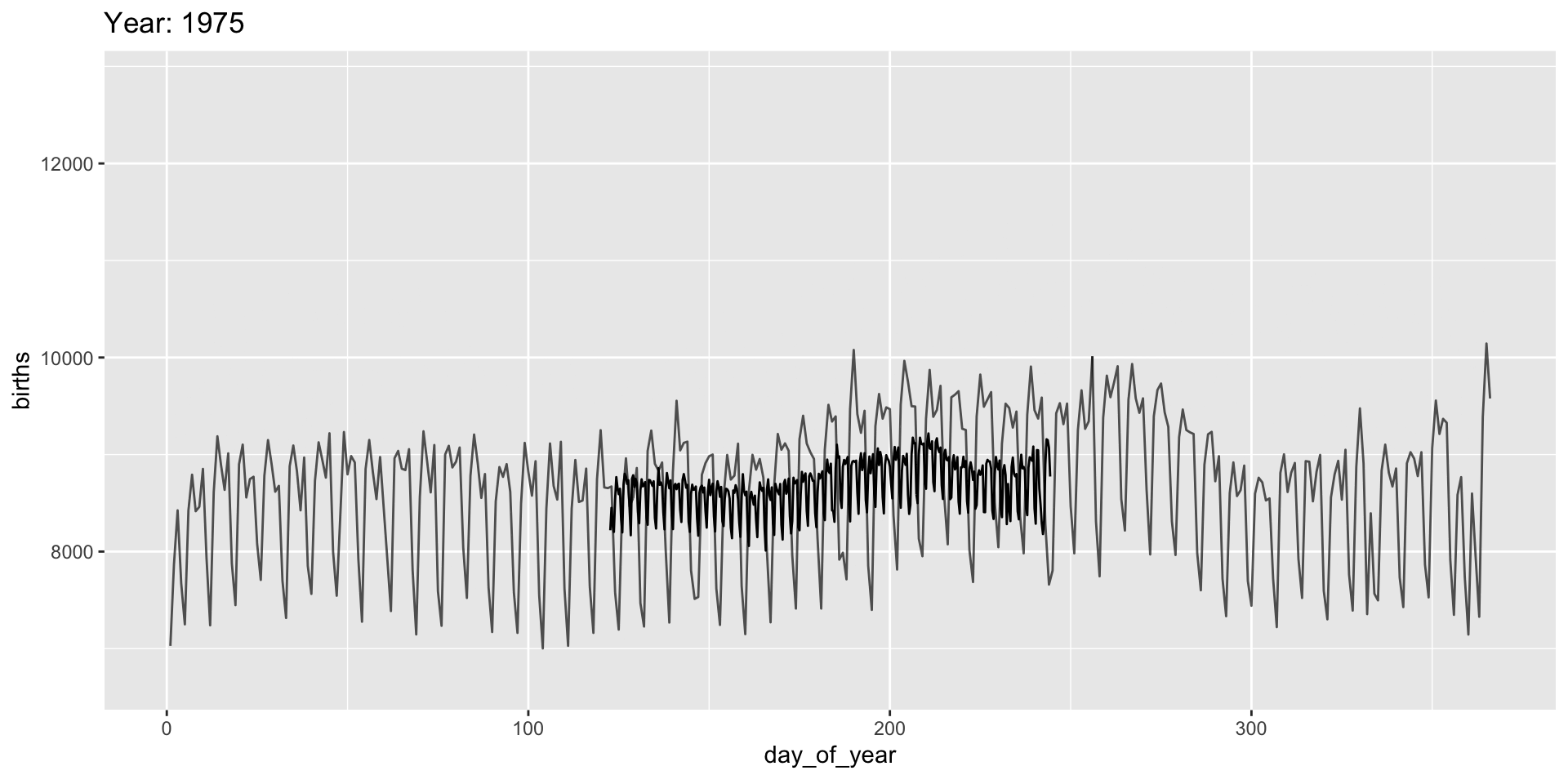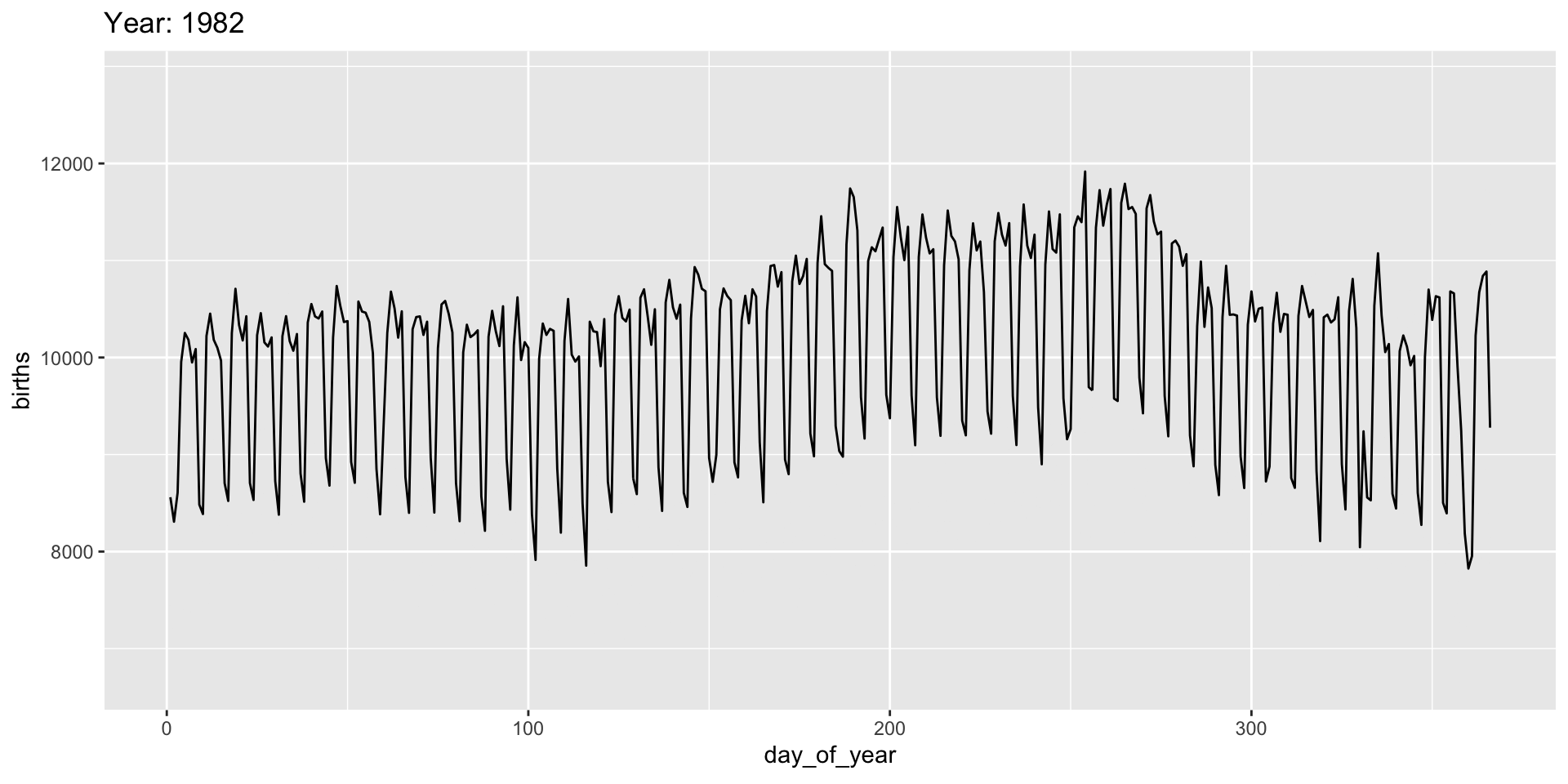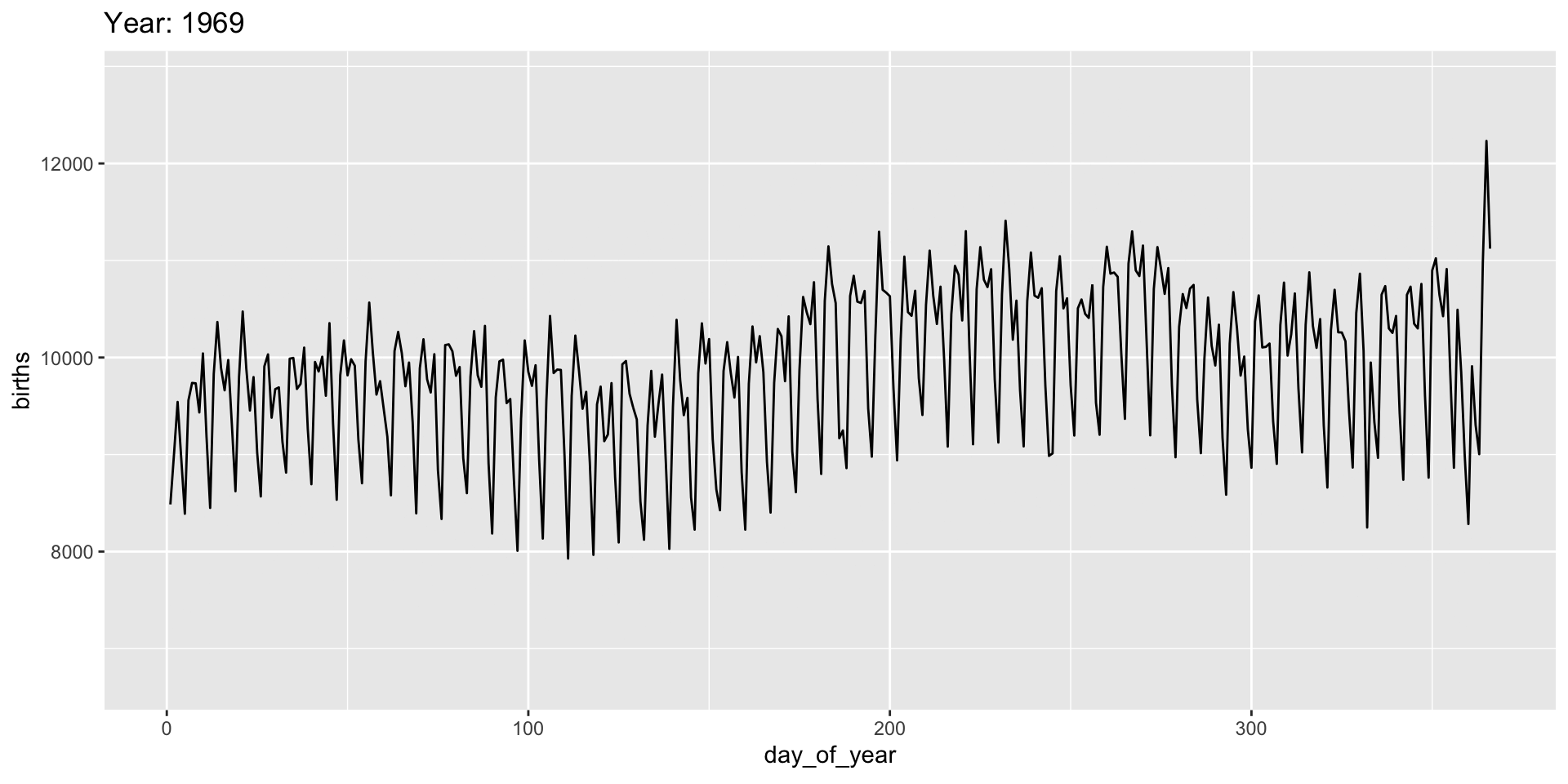
Animation is implemented via a new plot element: transition_*():
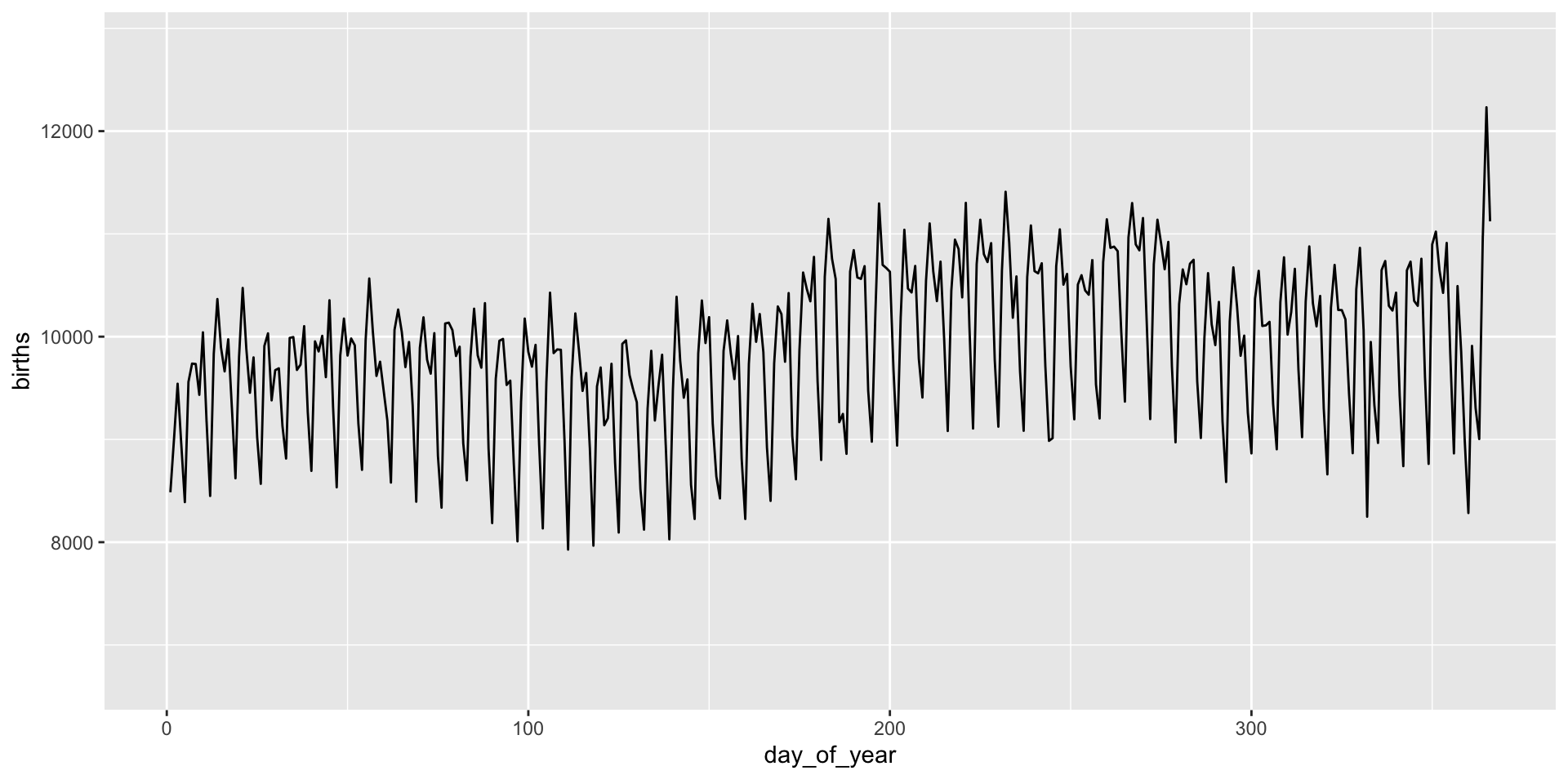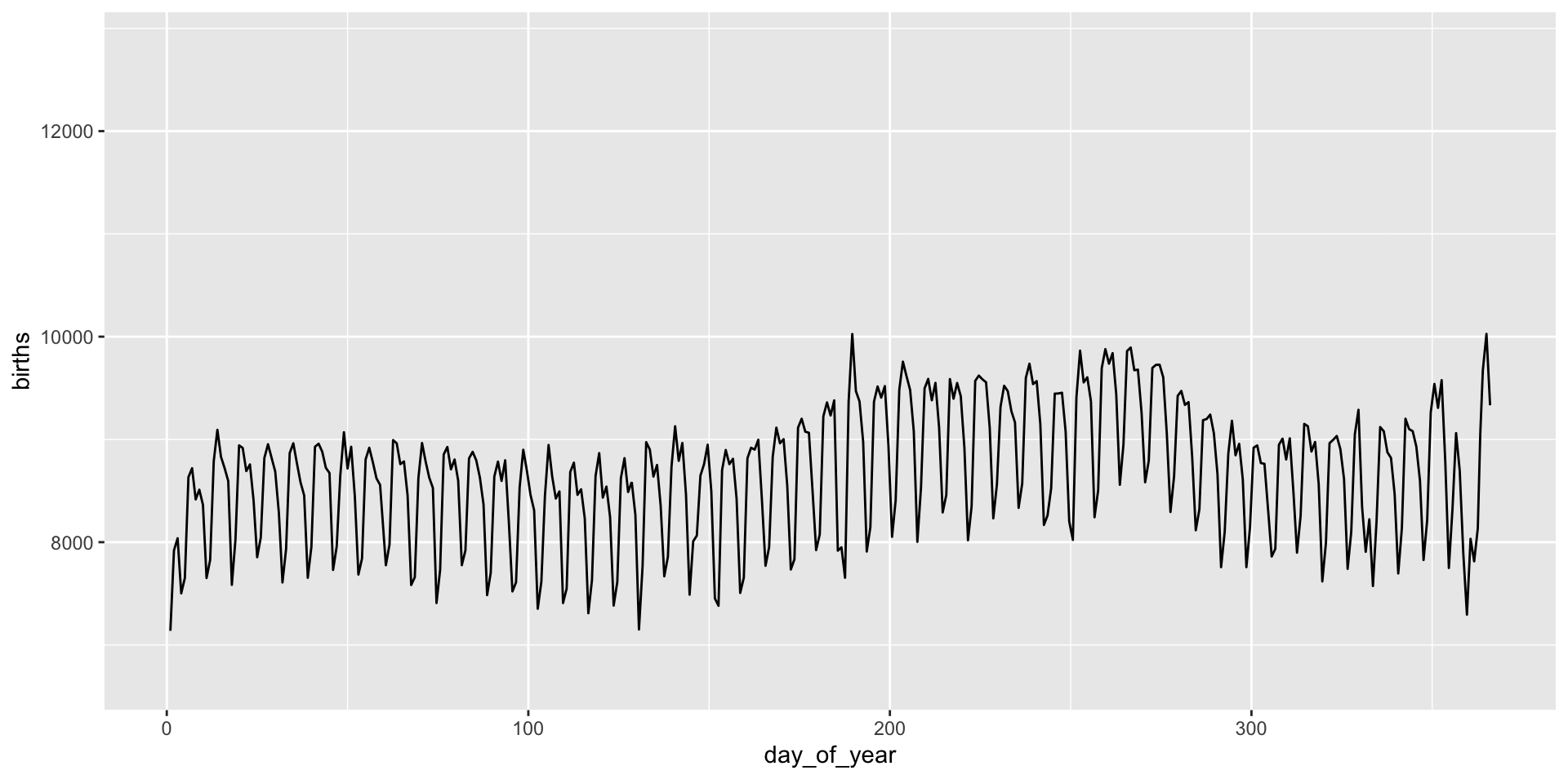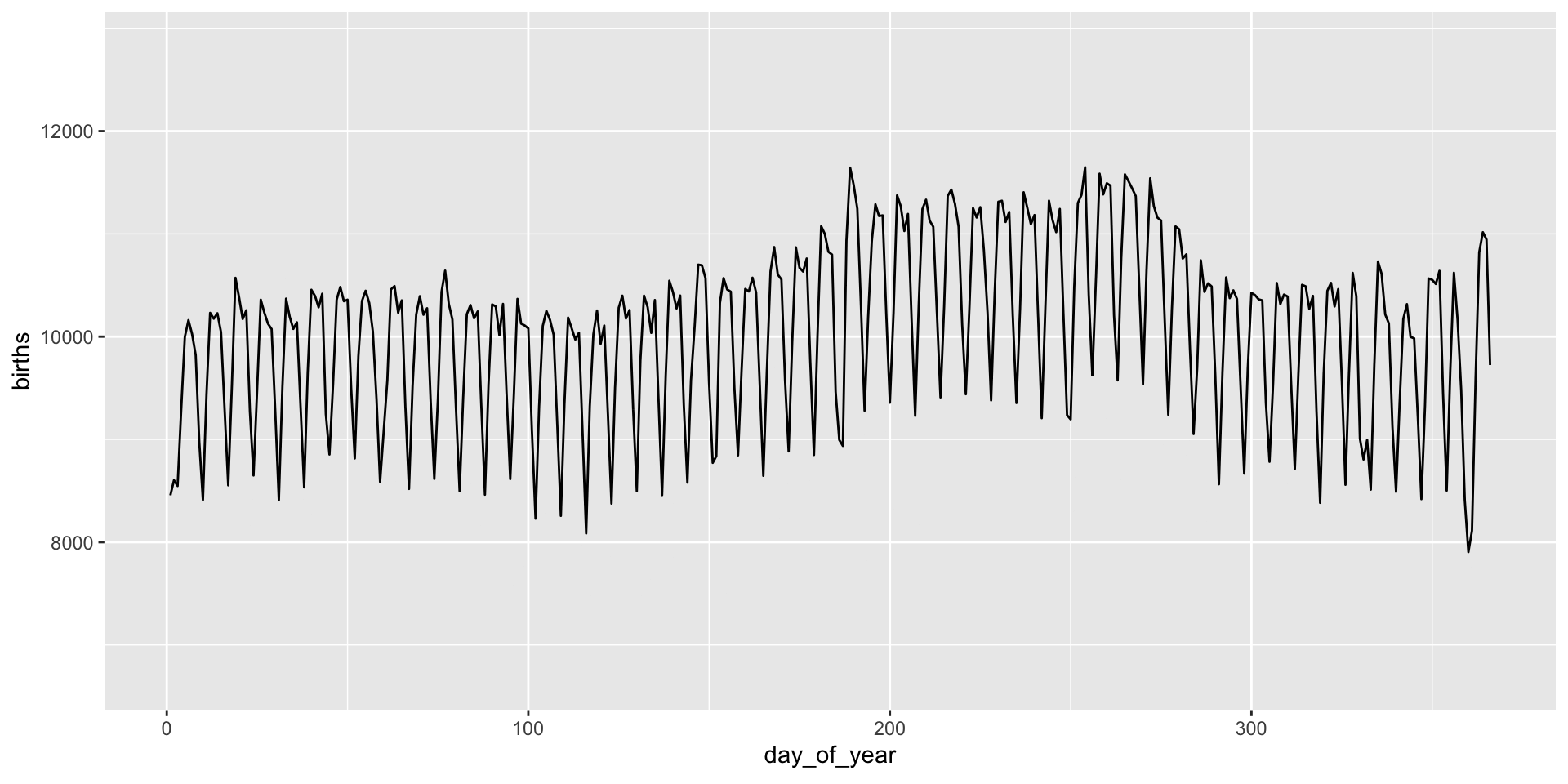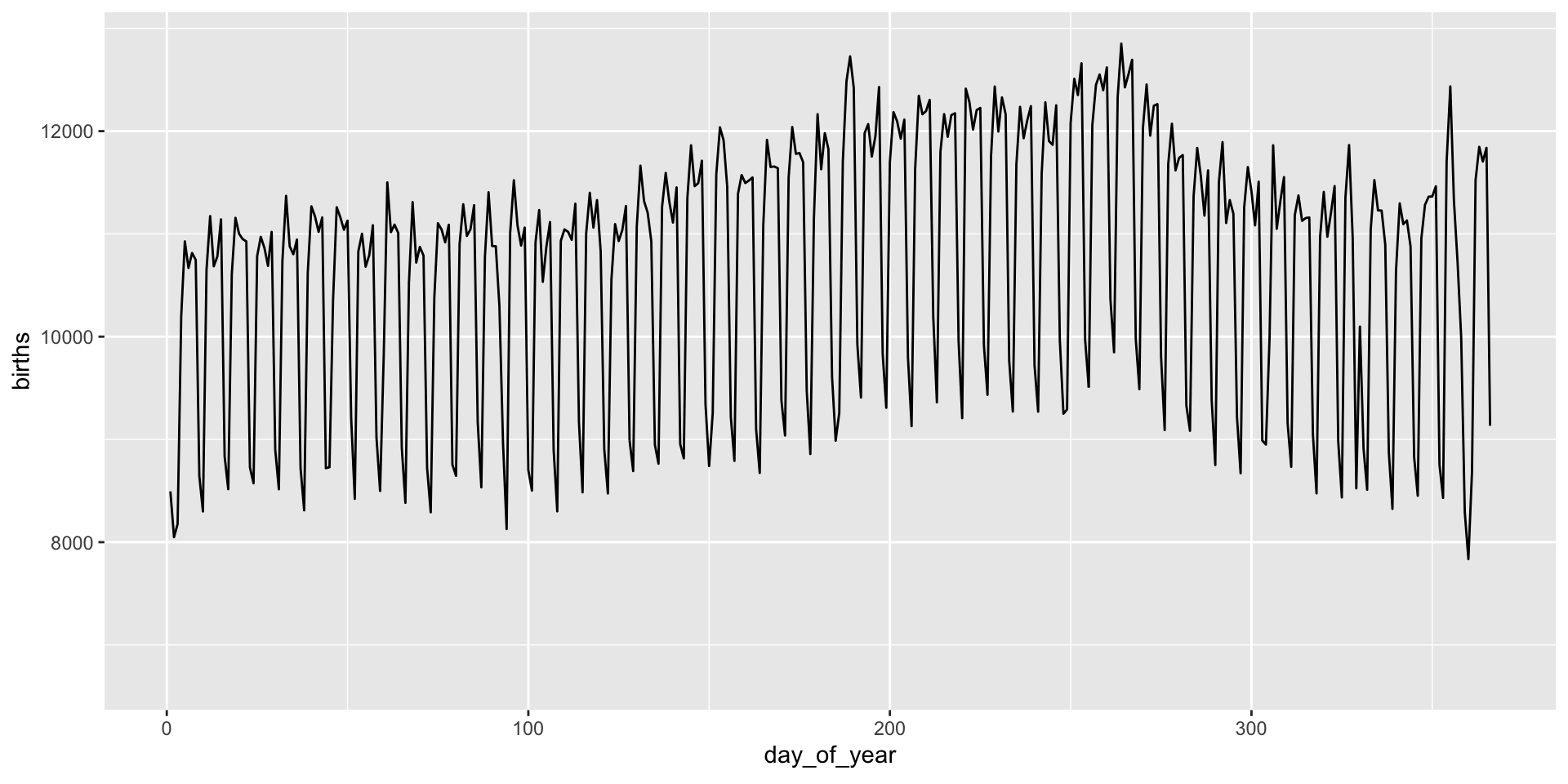
transition_*() functions
Add a title to indicate time being shown:
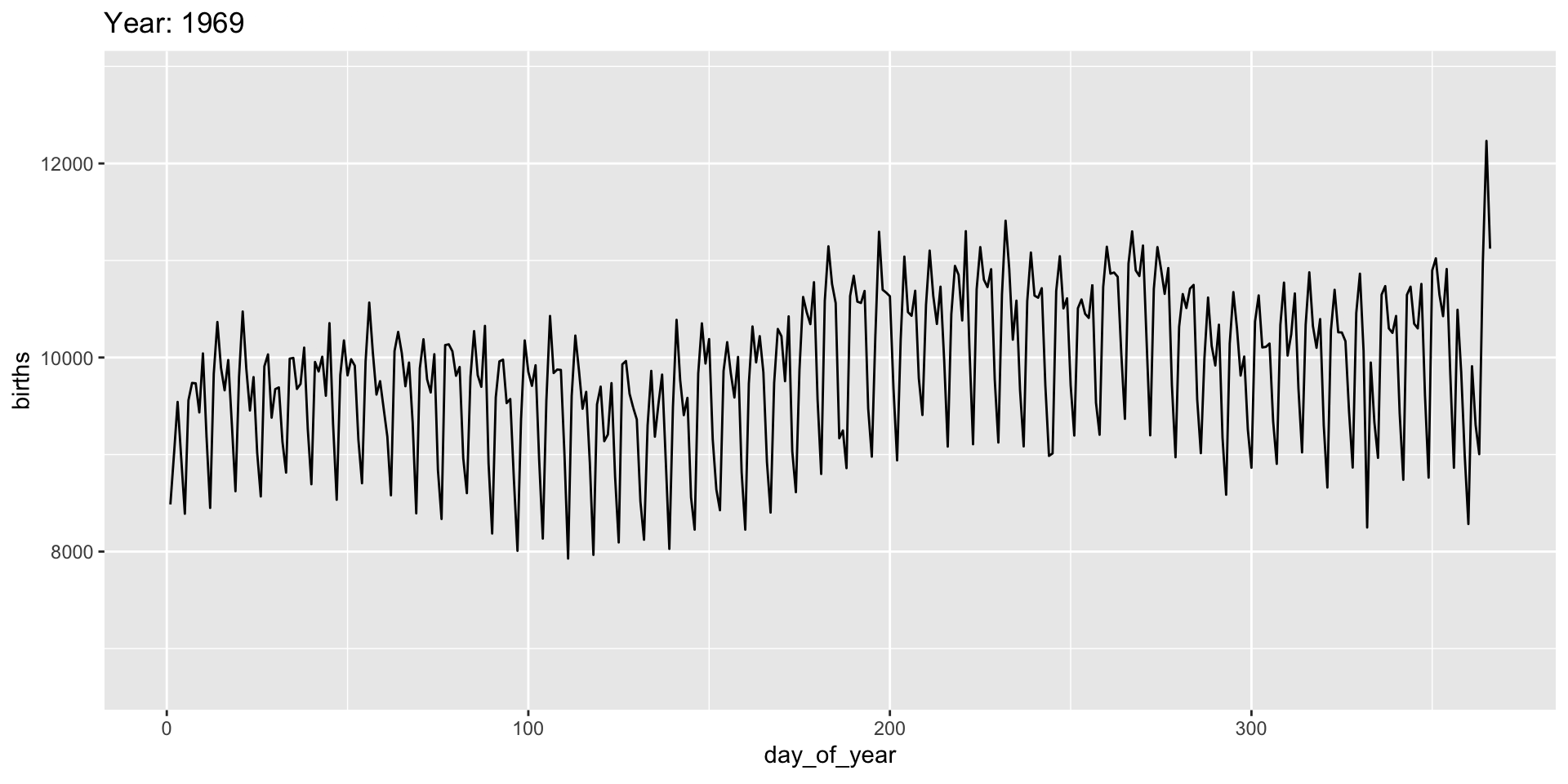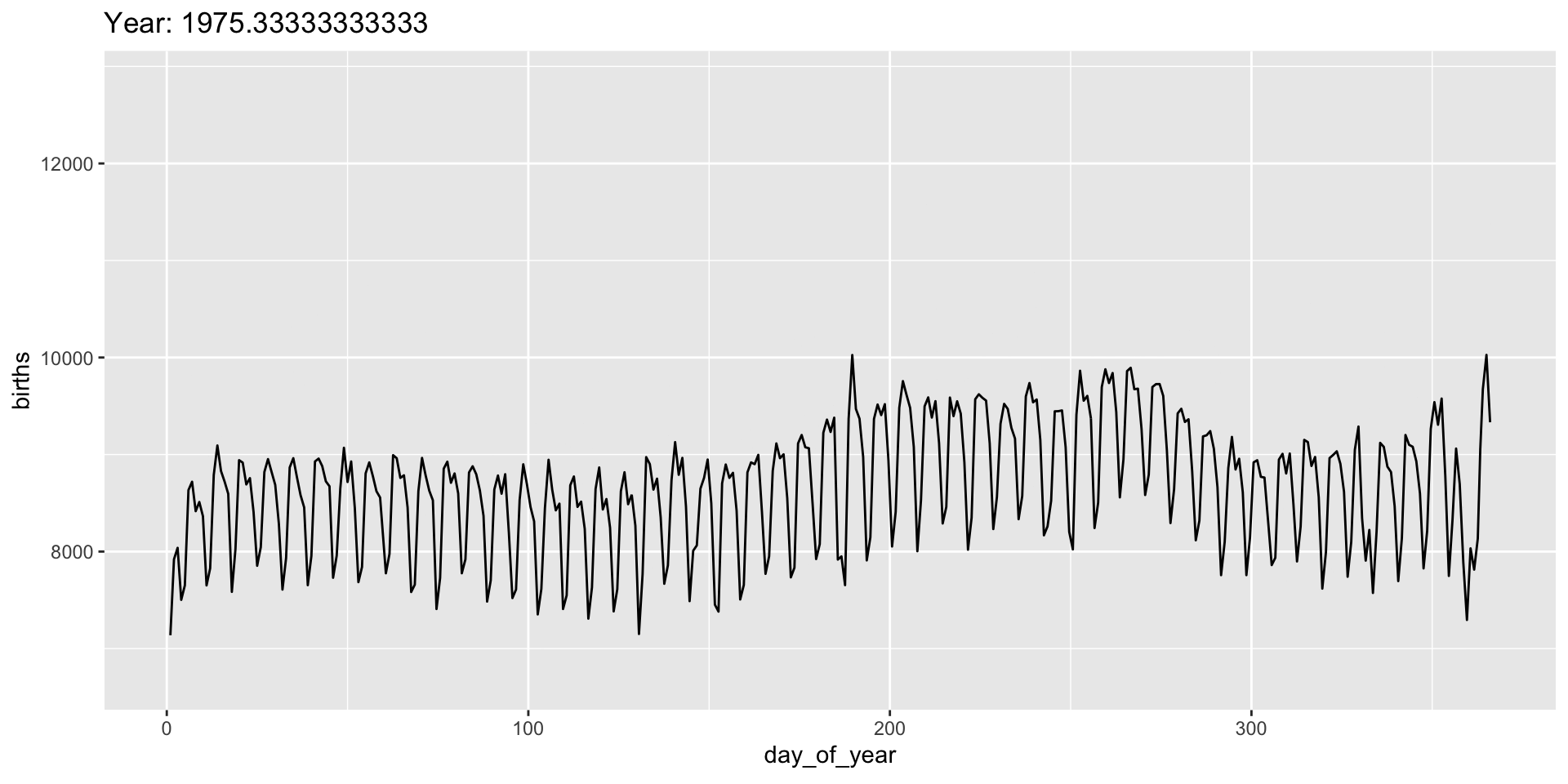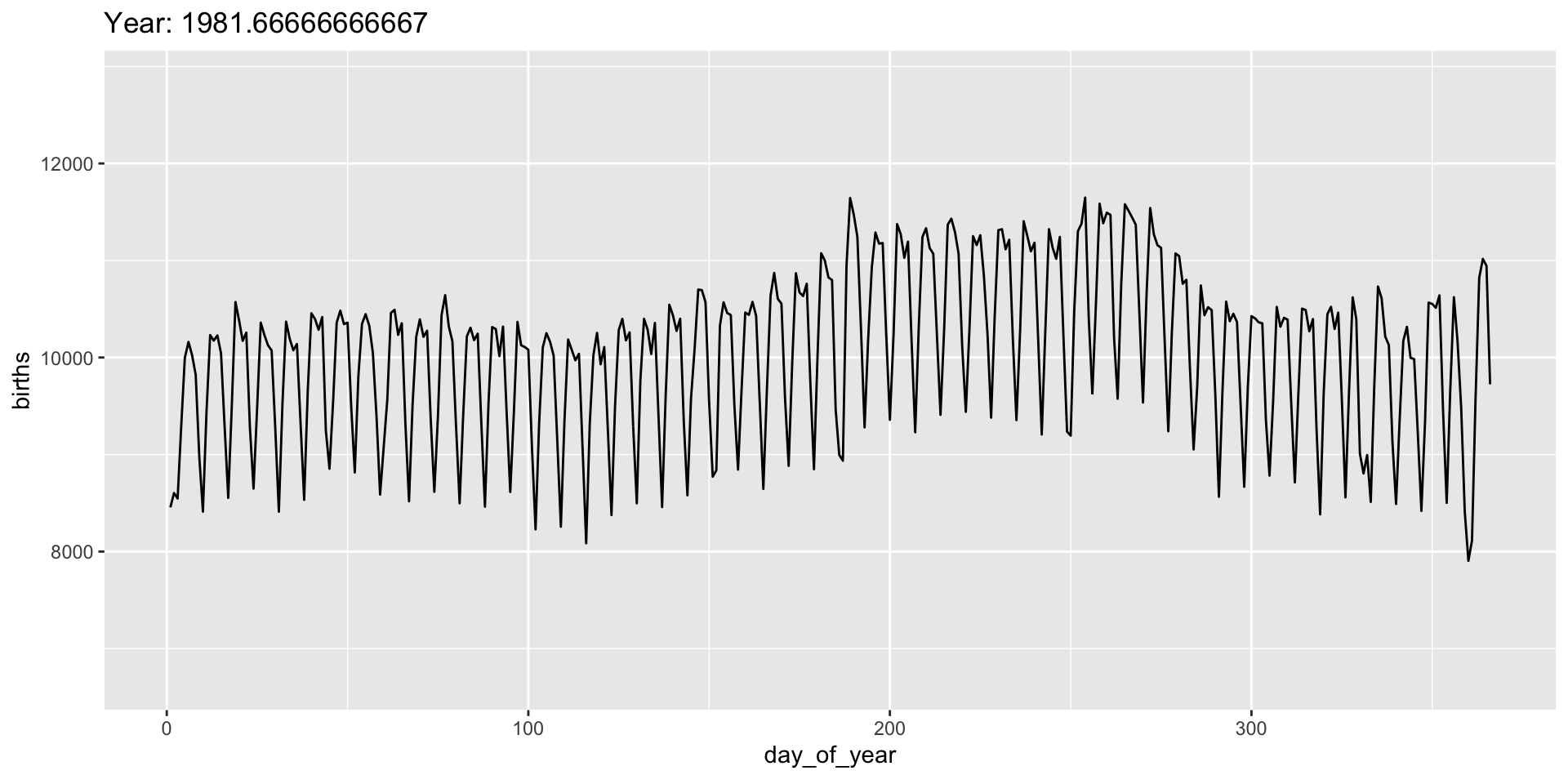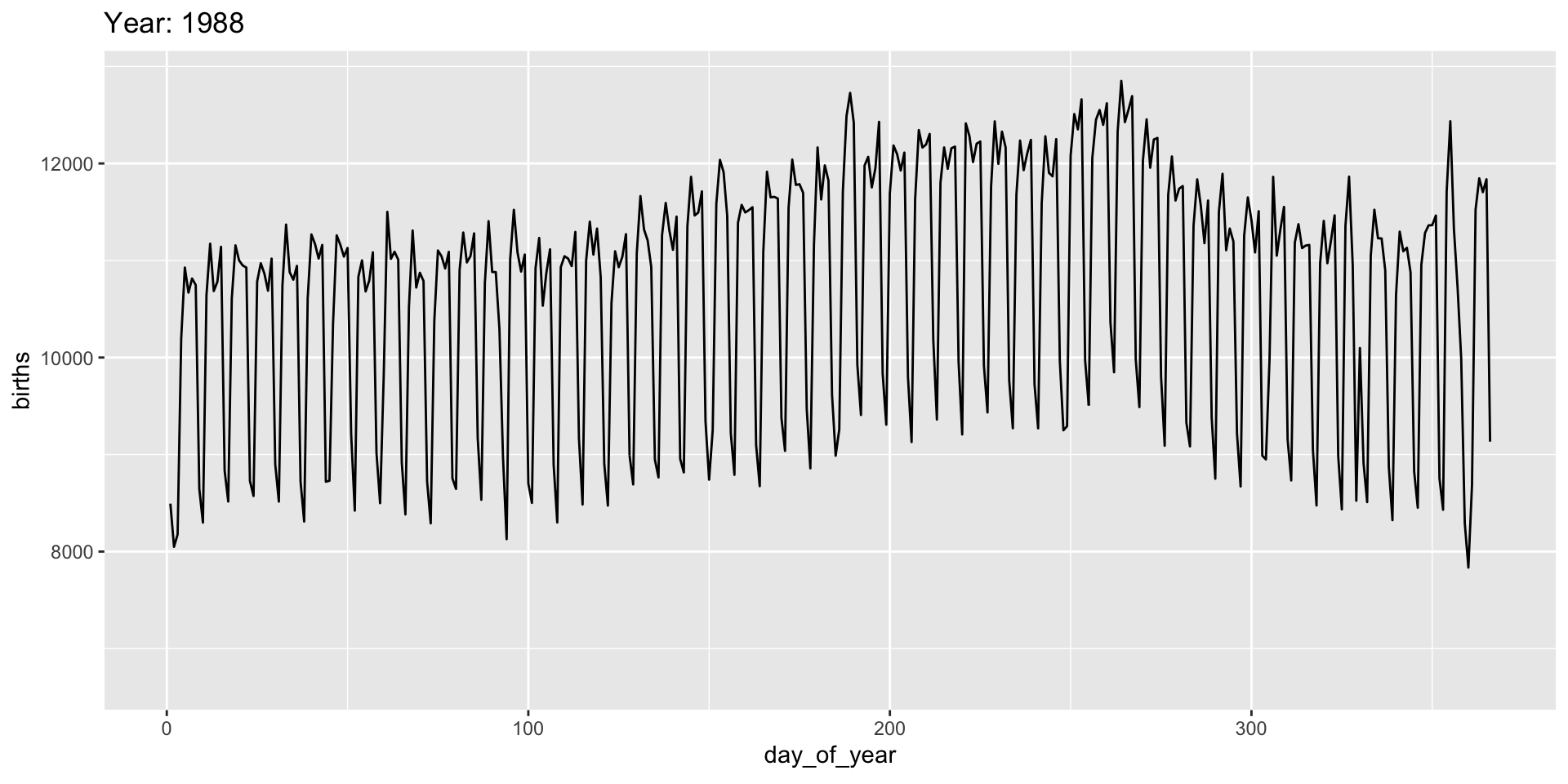
transition_*() functions
gganimate “tweens” (interpolates) between frames for smoothness - works best for continuous time data.
It’s a bit weird here and we might prefer a more discrete interpolation:
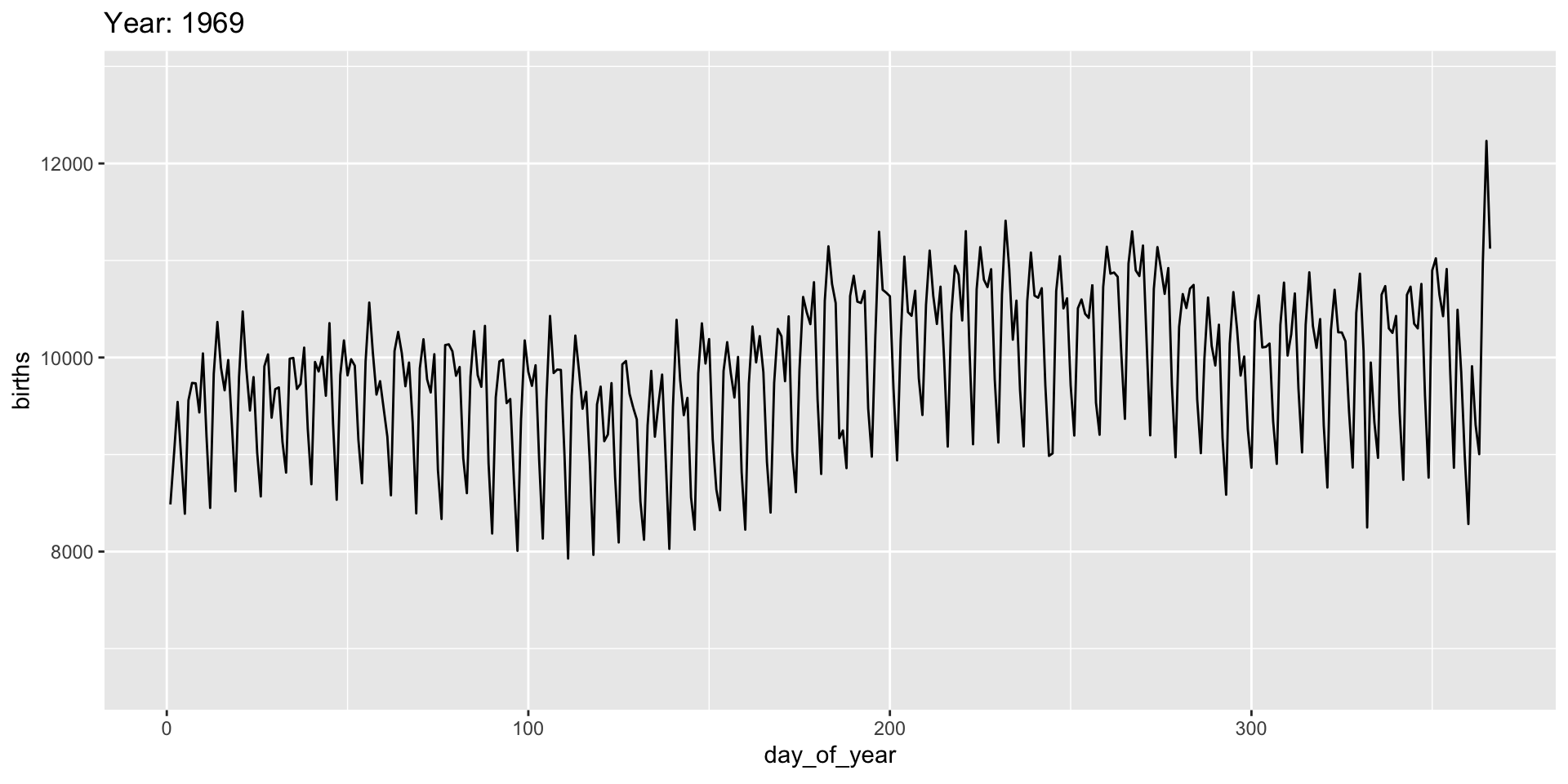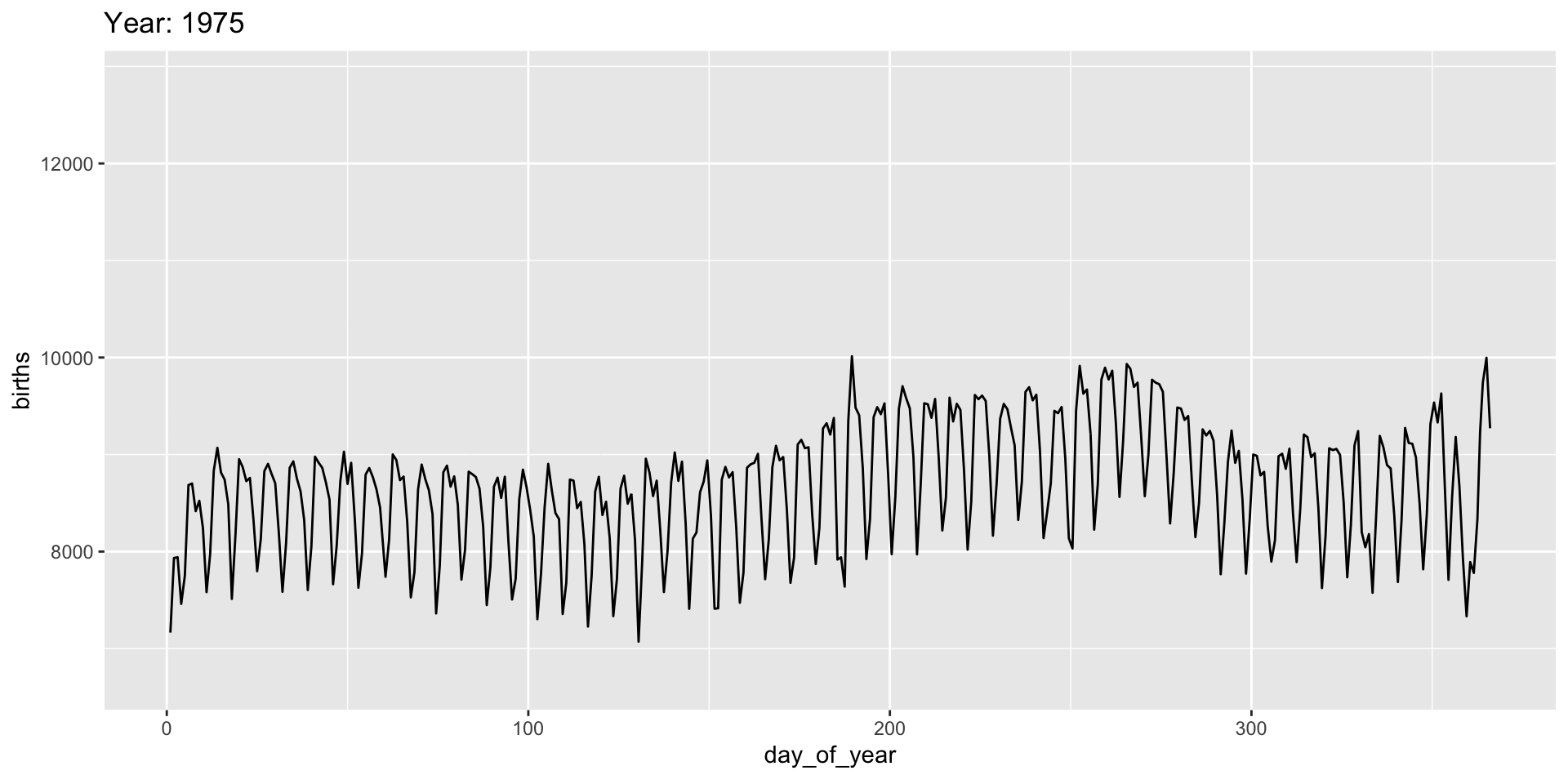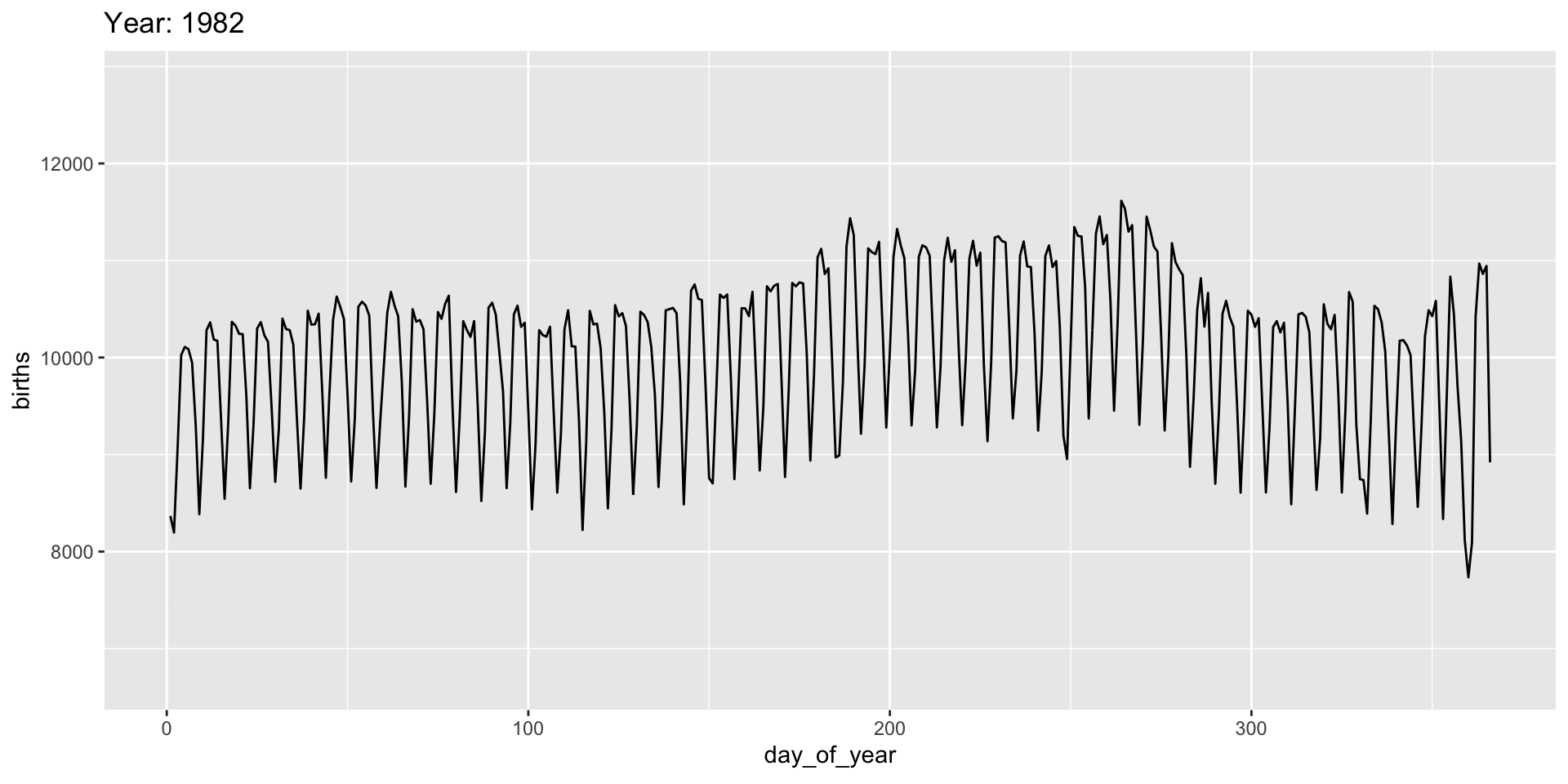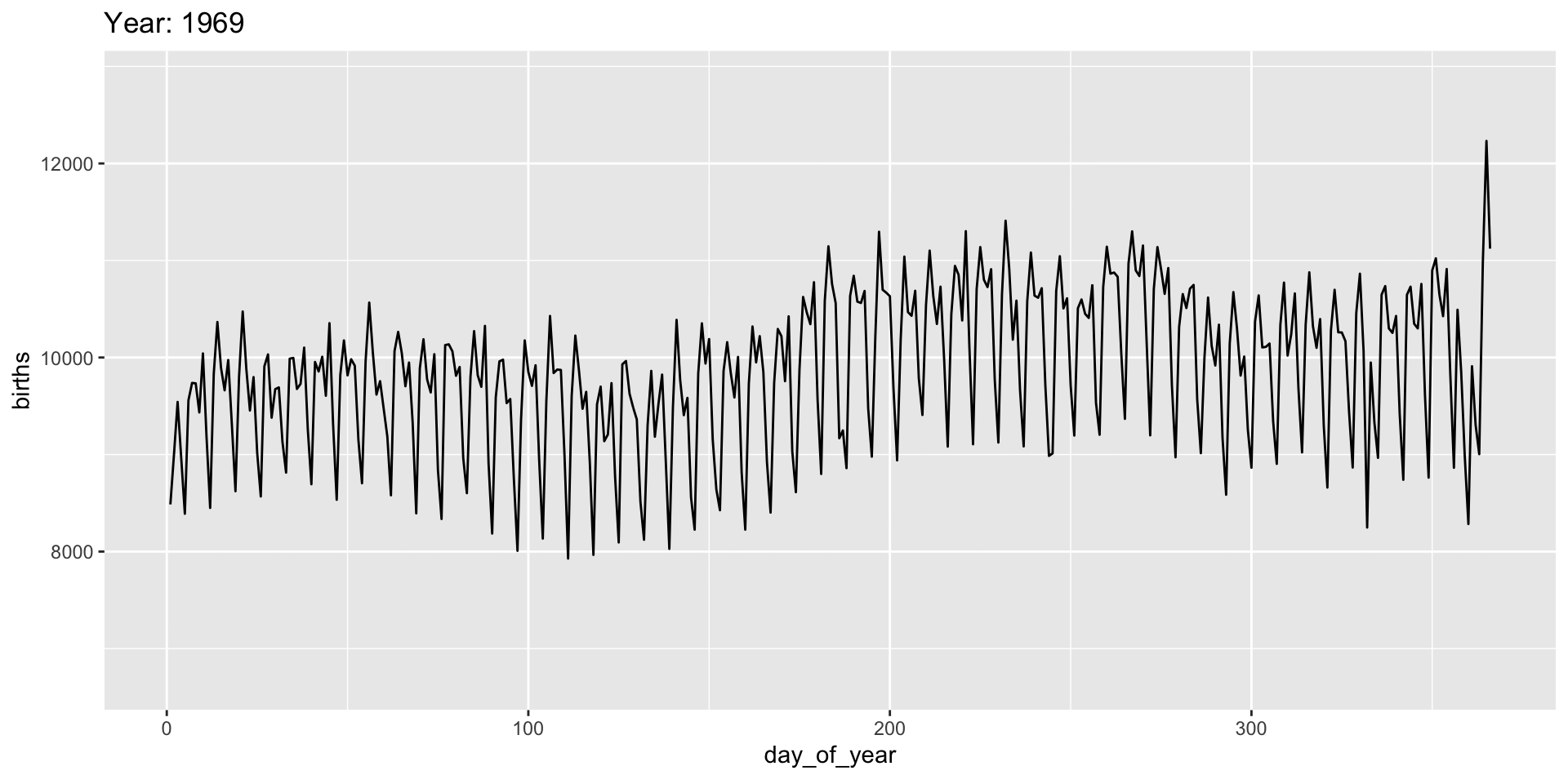
Easing
Use the ease_ functions (or enter_()/exit_*() separately) for finer control:
Grouping
The group variable is used to determine whether something is permanent over time.
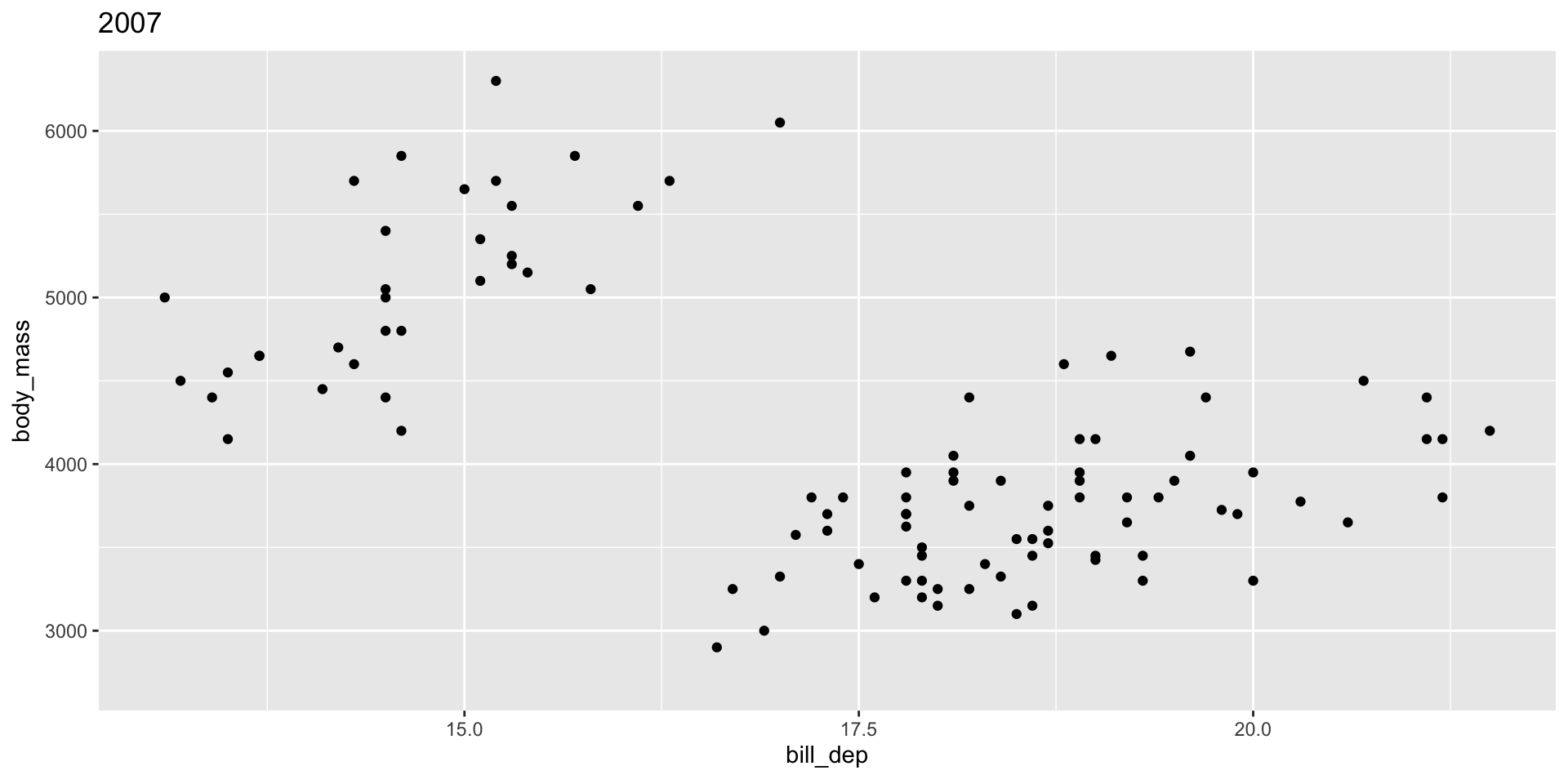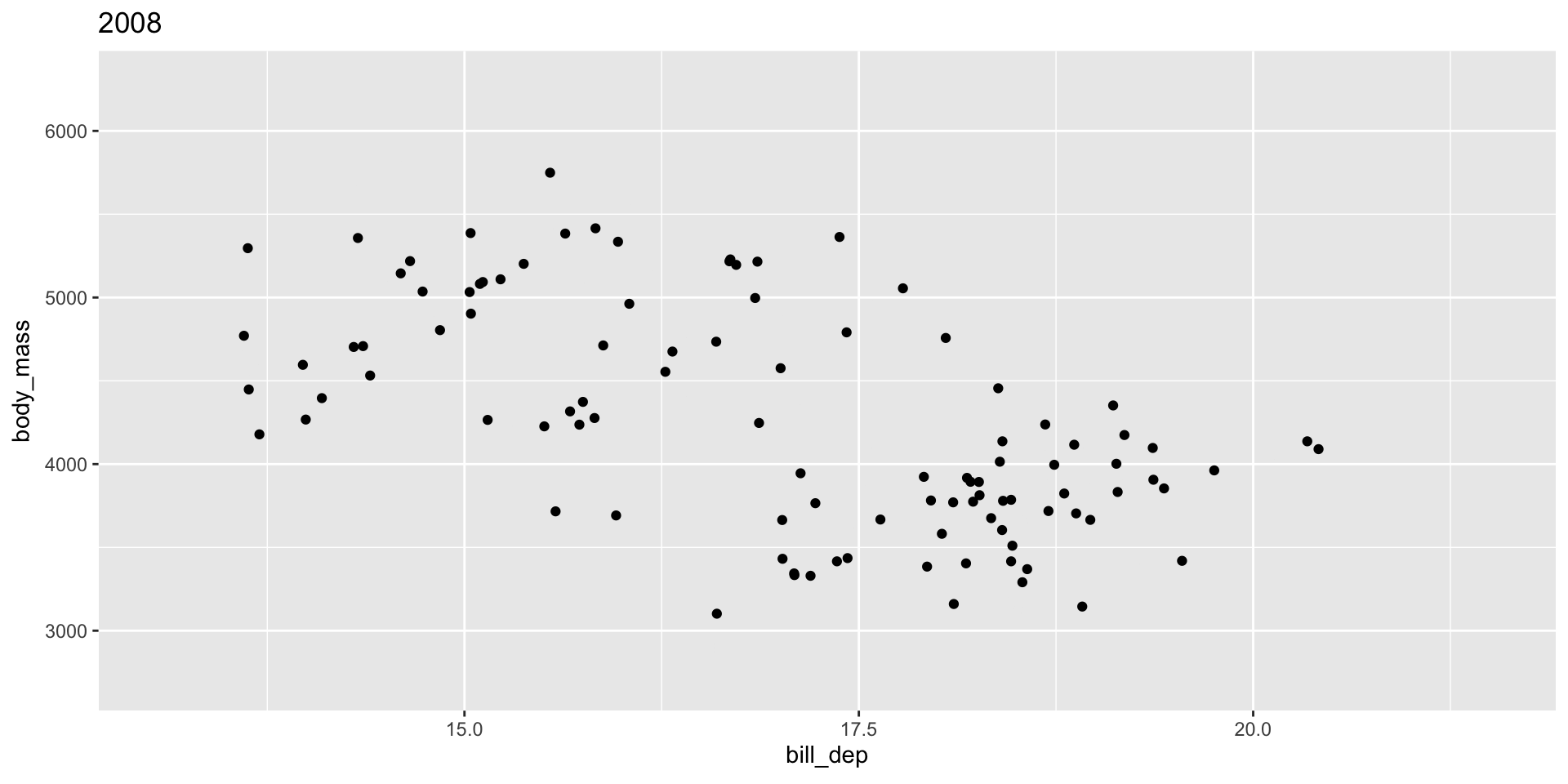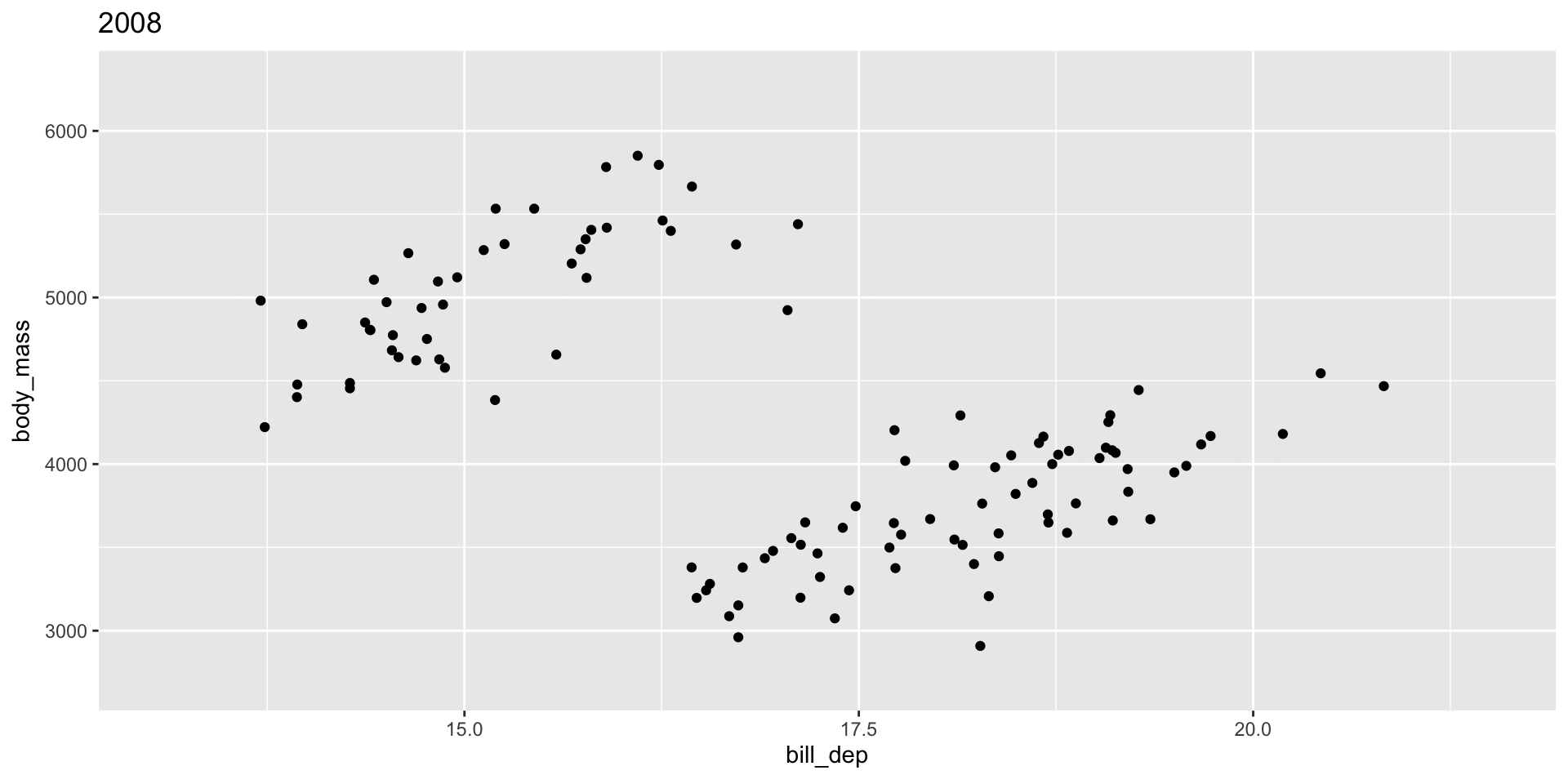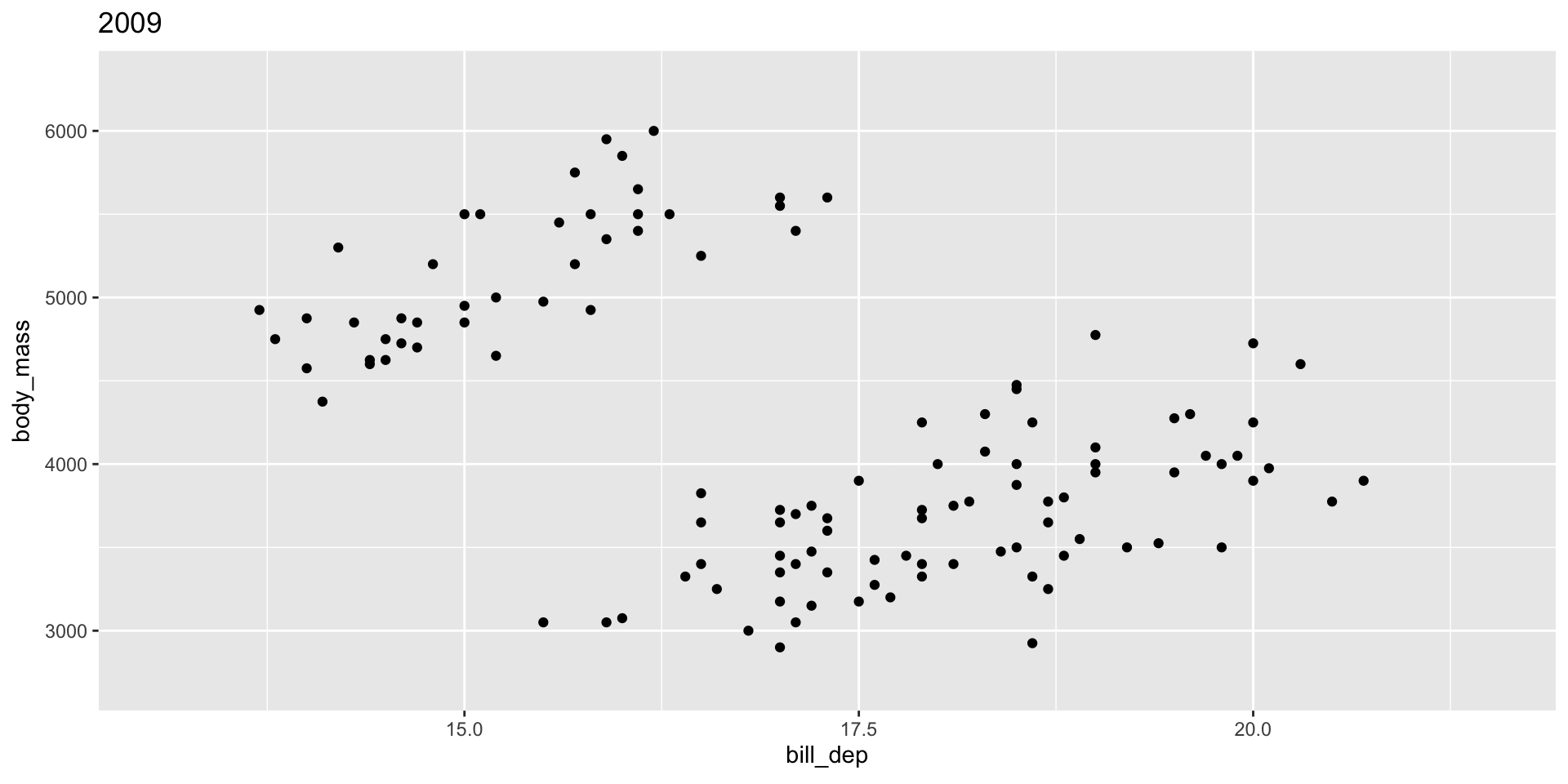
Bad! Doesn’t make sense to interpolate penguins
Grouping
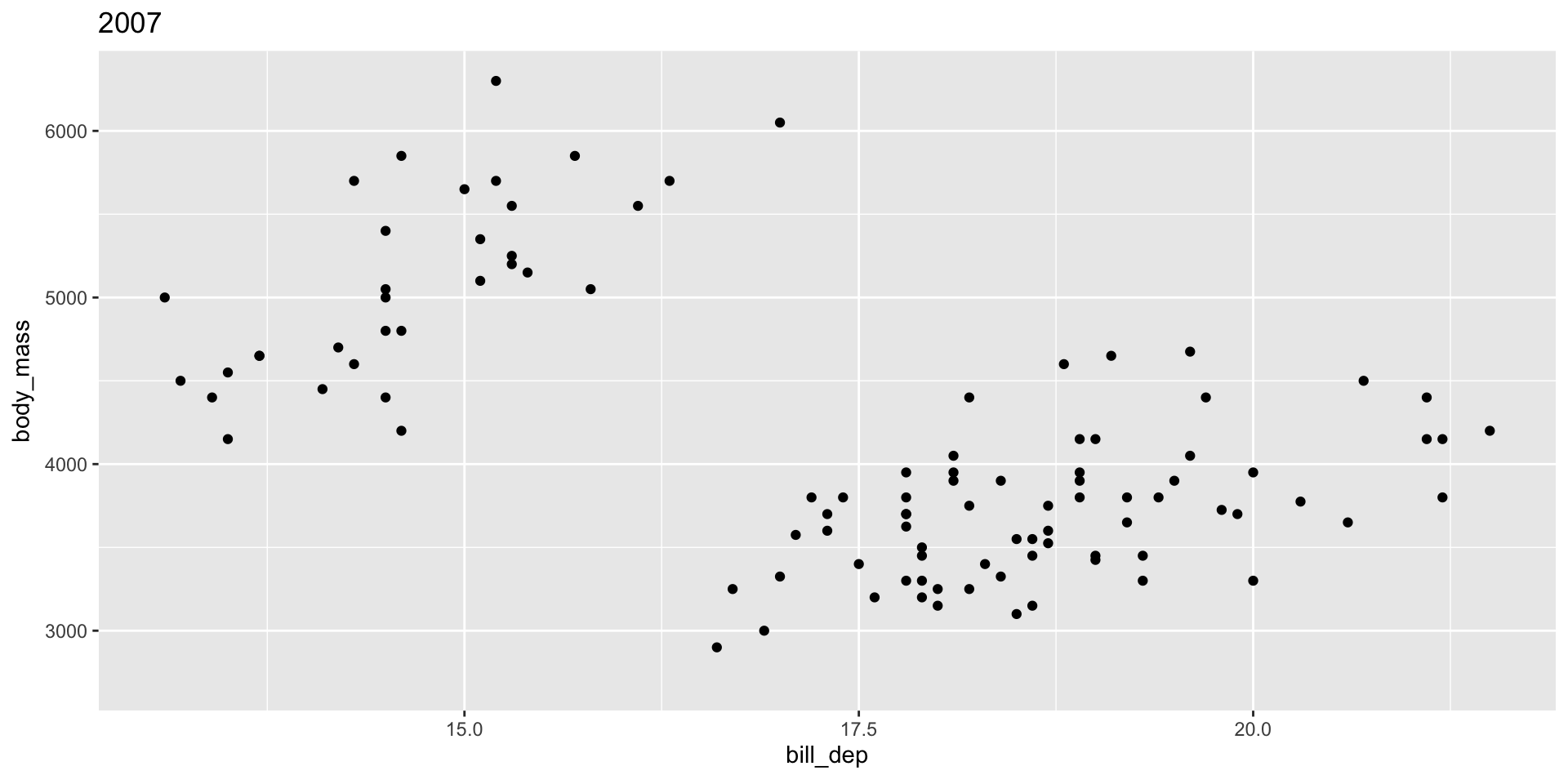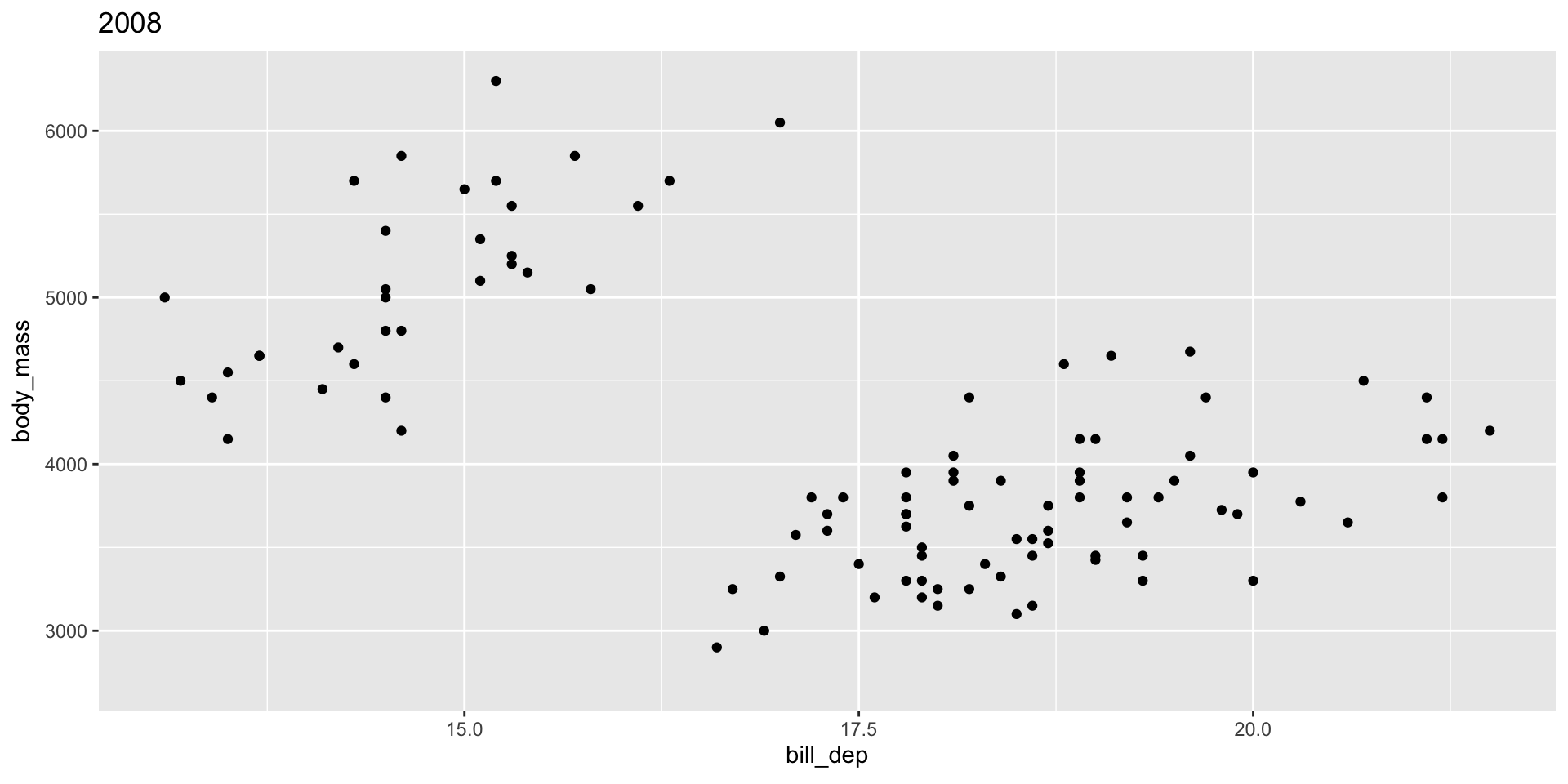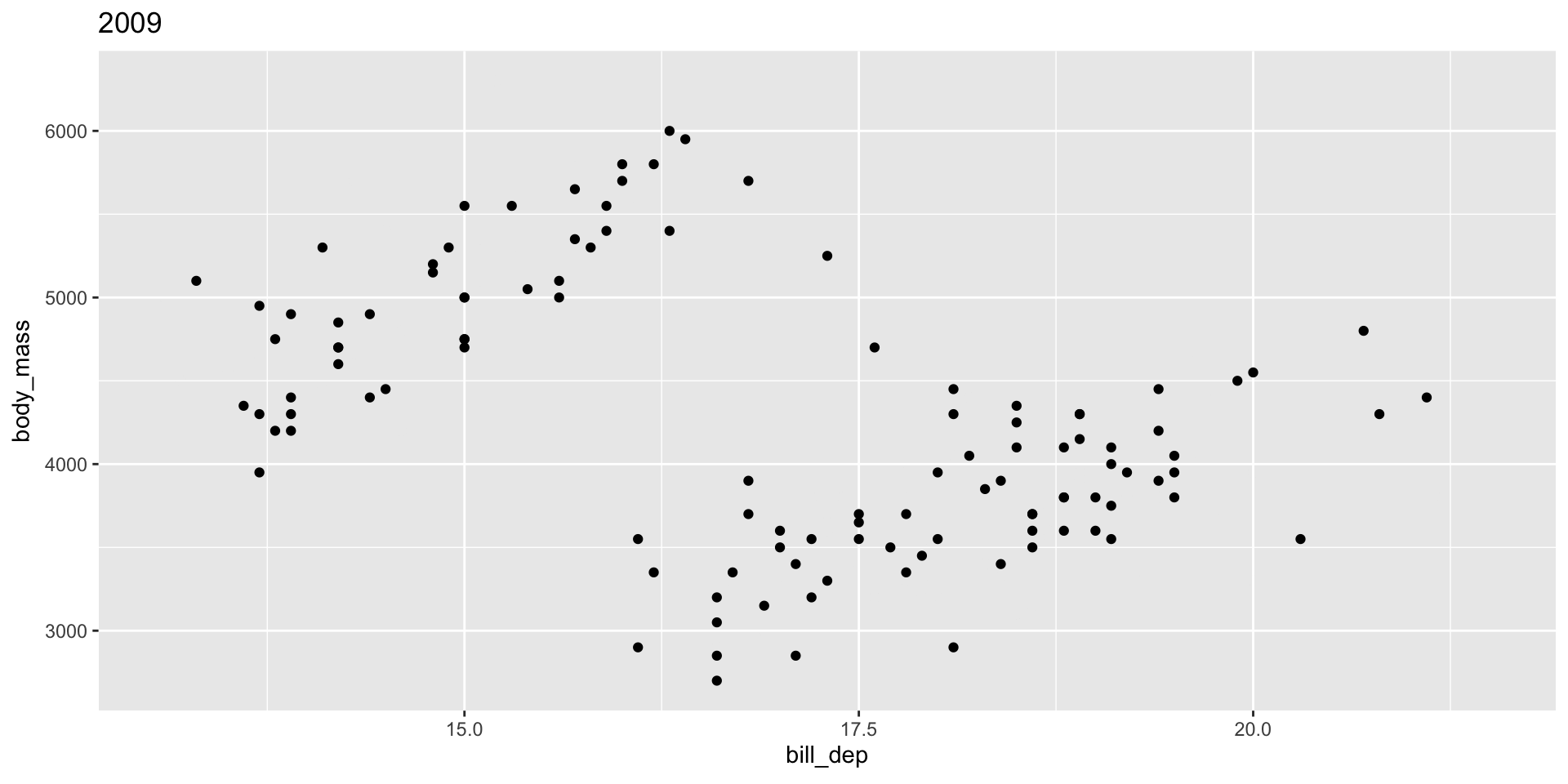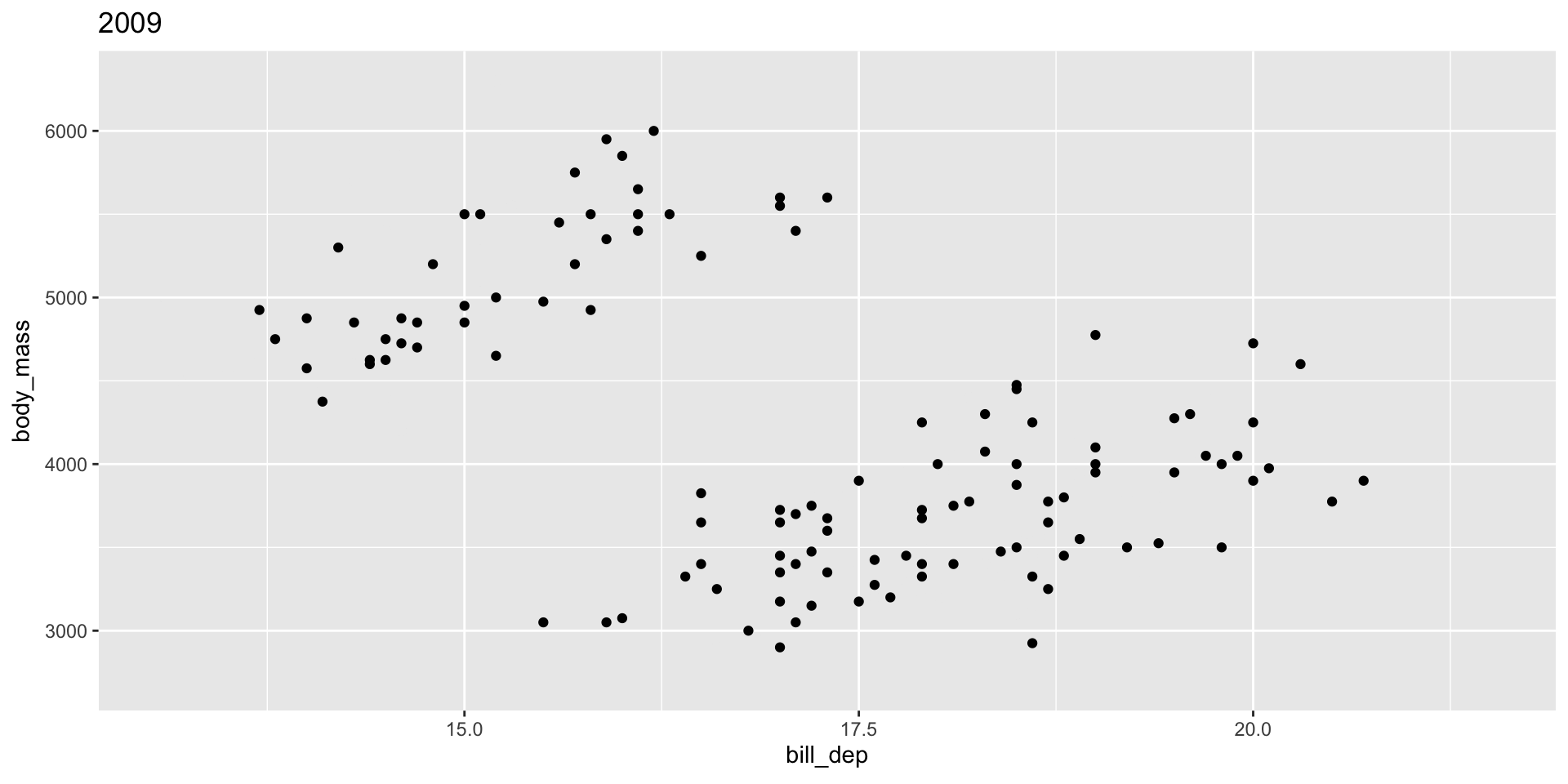
See gganimate Getting Started Documentation for more
ggplot2 Font Sizing
Theme machinery!
Custom ggplot2 Theme
Advanced:
theme_set()- changeggplot2defaults.Rprofile- set code to run every time you startR